These are my thoughts and key take aways from working with Azure Cosmos DB for a while now.
Infinite Ease
Creating a database importing some data and querying it through the Data Explorer takes literally 5 minutes.
Creating an interface using Azure Logic Apps with the Cosmos connector or a proper API using Azure Functions with bindings and PowerShell is an additional 5 minutes.
Expose the API through the Azure API Management Gateway and you have a complete schema-less database and data access layer in 15 minutes.
Cosmos is hands down the most easy and accessible database technology I’ve ever worked with – period!
Infinite Scale
Cosmos is built to be infinitely scalable in terms of storage and performance.
Data is stored in storage partitions in chunks of 10GB and Cosmos automatically adds more storage partitions as needed. It works great and is seamless – only gotcha is that Cosmos for some reason won‘t scale storage partitions back to less than two which in most cases probably doesn’t matter much, but it is an issue with regards to cost. See more below.
Performance is measure in a fixed unit called Request Units per Second or RUs. 1 RU is required to read 1 KB of data and 5 RU are required to write 1KB of data. So on the surface calculating how many RUs you need should be easy. Turns out it isn’t and missing your RUs can be costly or make you loose data.
Infinite Cost
This is where infinite scale turns into infinite cost. On the surface it only seems fair that infinite scale should have a price – but controlling cost in Cosmos is difficult and completely different for what you have come to expect of the Cloud.
It’s all about those RUs.
You allocate a fixed amount of RUs either to an entire database (probably can’t recommend doing that) or to individual collections – and then you pay for those fixed RUs whether you use them or not!
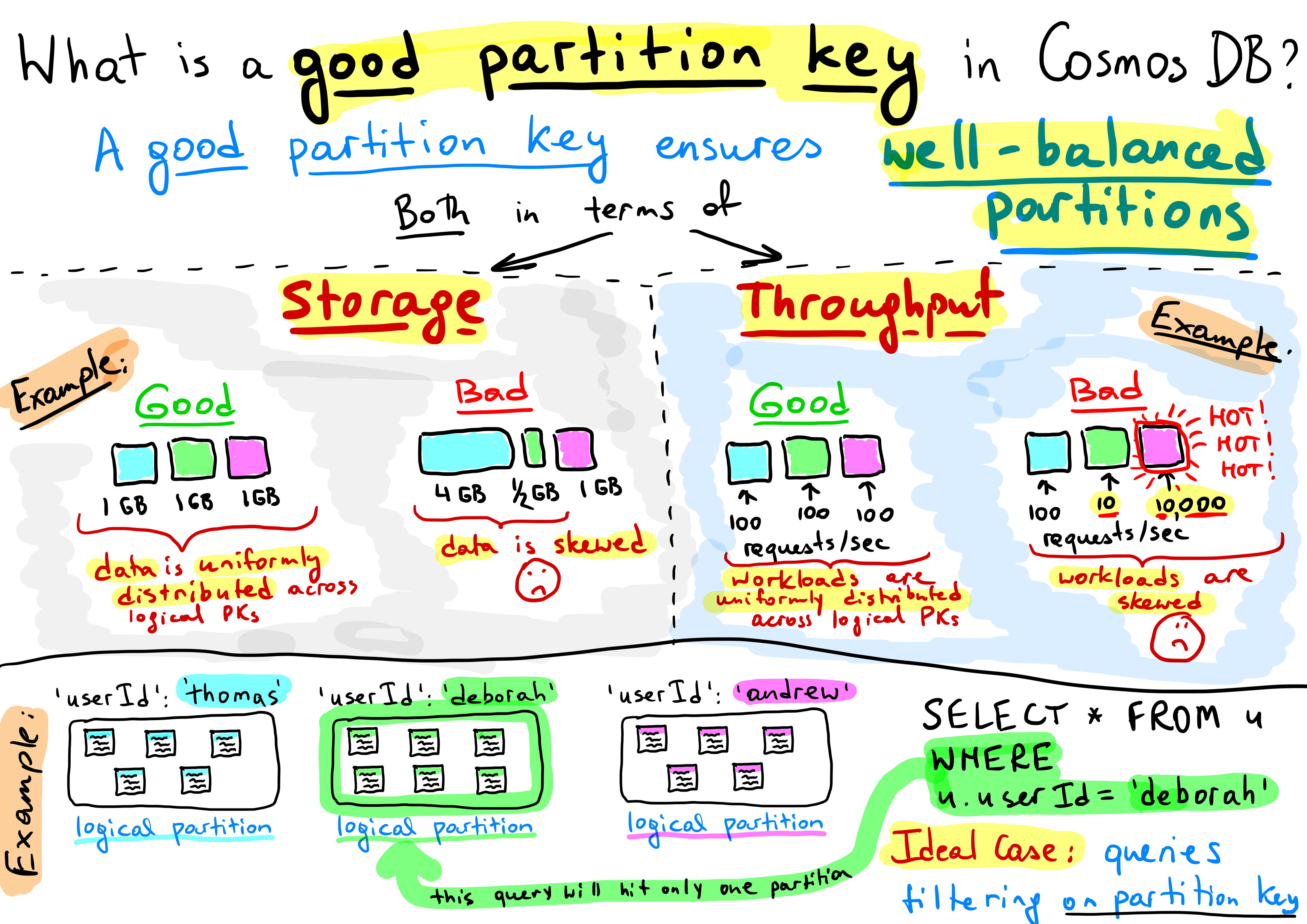
Fine you think – how much can it cost in terms of RUs to write and read some data? Quite a lot in fact and there are several factors which have great influence over how many RUs are required to write and read data. I highly recommend reading this and this but it all boils down to the partition key.
The partition key is used to distribute data over logical data partitions when Cosmos writes data. The less data you write to the same logical partition as the same time – the more performant the write is.
When reading data the partition key can be used in a query to tell Cosmos where the data is stored and make reading data more performant. If you don’t know the partition key in a query then Cosmos have to read through all the data that fits the WHERE clause and that drives RUs – because reading 1 KB costs 1 RUs – so reading through 1000s of KBs of data to find that single document can cost a lot of RUs. So if you have a lot of queries without partition key and lots of spikes then you have to provision lots of RUs and pay for them 24/7.
Unfortunately there’s no auto scaling for RUs available in Cosmos even though the competitor seems to have one. However recent additions to Azure Monitor makes it possible to create your own.
Update: At Ignite 2019 CosmosDB AutoPilot was announced which is the long awaited auto scaling feature!
If you have spikes and you run of out provisioned RUs then Cosmos will throttle the requests by sending back an HTTP429 error message. It’s then up to the client to know how to handle this and perform a retry. If the client doesn’t know how, then it’s an error and the data is probably lost. Please be aware of the retries!
Infinite Possibilities
Once you’ve tackled the scaling, cost and partition keys and you start to to use Cosmos with the change feed and hook it up to the event grid – you get a completely new publish and subscribe data layer capable of replacing integration middleware, ingesting data at IoT scale and driving real time data analysis with Spark and Databricks.
Cosmos is a game changer!









{kind=link}
{kind=link}